Gesamtbetrag:
zzgl. Mwst.
Künstliche Intelligenz braucht keine Supercomputer und häufig sammeln Unternehmen bereits heute Daten, aus denen sich mit Hilfe eines KI-Modells wertvolle Erkenntnisse gewinnen lassen. Unser KI-Kompetenzzentrum bietet Ihnen viele Vorteile zur Implementierung von KI in Ihr Embedded System:
- Inhouse Data Scientist als direkter Ansprechpartner
- KI-Kits für Data Mining
- KI-Schulungen + Online-Seminare
- Agiles Team für Software + Hardware-Entwicklung
- Analyse + Lösungsberatung
KI-Kompetenzzentrum _ Unser spezialisiertes Know-how für Ihre Entwicklung
Vom Modell
zur Embedded
KI-Anwendung
Um unseren Kunden die Möglichkeiten von KI-Lösungen nahezubringen und die bestmögliche Unterstützung aus einer Hand zu bieten, haben wir ein Kompetenzzentrum für KI gegründet. Das Team rund um unseren hauseigenen Data Scientist Dr. Jan Werth mit langjähriger Erfahrung in der Nutzung von Künstlicher Intelligenz zeigt Ihnen die Möglichkeiten von Machine Learning und findet die passende Lösung für Ihr Projekt. Entsprechend Ihrer eigenen Wünsche und Kompetenzen ergänzen wir das Team agil mit Cloud- und Security-Experten sowie Soft- und Hardware-Entwicklern.
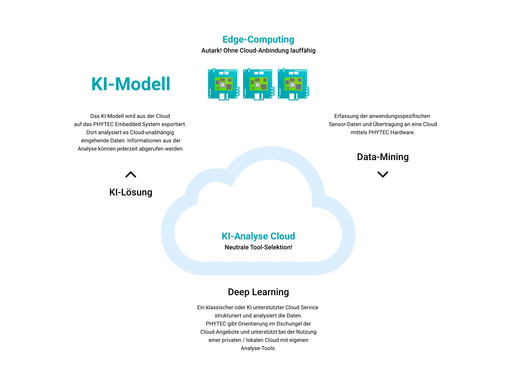
CLOUD-Computing
Cloud-Computing bezeichnet die Verlagerung der Rechenleistung in die Cloud. Die Ergebnisse können direkt online distribuiert werden.
EDGE-Computing
Beim Edge-Computing werden die Daten am Entstehungsort verarbeitet. Die Modelle zur Verarbeitung können per Cloud-Computing entstanden sein, laufen jedoch lokal. Eine Cloud-Anbindung ist möglich, aber nicht zwingend notwendig. Damit eignet sich Edge-Computing auch für sicherheitskritische Anwendungen.
Sie haben Fragen zum Einsatz von KI
oder benötigen Unterstützung für Ihr Projekt?
Das PHYTEC KI-Kompetenzzentrum hilft Ihnen gerne weiter.
KI, Machine & Deep Learning _ Gibt es schon lange. Warum jetzt? Was hat sich geändert?
Die Grundideen und Algorithmen von maschinellem Lernen sind seit langem bekannt. In den letzten 50 Jahren haben sich allerdings entscheidende Rahmenbedingungen geändert, die nun zum rasanten Erfolg von KI führen:
- Gestiegene Rechenleistung
- Liberalisierung der Rechenleistung durch Cloud-Computing
- Adaption der Rechenleistung
- Exponentielle Datenzunahme
- Kostengünstiger Speicherplatz
- Benutzerfreundliche Open-Source-Analysetools
Die gestiegene Rechenleistung ermöglicht es, die ressourcenfordernden Rechenprozesse in überschaubaren Zeiten zu bewältigen. Ebenso wichtig ist die Liberalisierung der Rechenleistung, die es jedem Anwender ermöglicht, komplizierte Modelle bewältigen zu können, ohne zuvor eine leitungsstarke Infrastruktur aufbauen und warten zu müssen. Heute leihen wir uns Rechenleistung – und zwar genau so viel wie wir brauchen und nur für den notwendigen Zeitraum. Gleichzeitig steigt die Datenmenge exponentiell an, die wir zum Trainieren moderner Algorithmen zur Verfügung haben. In den Letzten zwei Jahren wurden geschätzt 90% aller Daten generiert. Ab dem Jahr 2018 wurde die zwei Zettabyte Marke an Daten überschritten. Das bedeutet, dass nach 2018 jährlich über zwei Zettabyte an Daten generiert werden. Diese Datenexplosion nährt den Erfolg von daten-hungrigen Algorithmen wie dem Deep Learning. Wichtig ist auch, dass Open Source Plattformen wie Phyton für die Verwendung von Machine Learning optimiert wurden. Seit 2015 ist mit der Einführung von Keras und TensorFlow auch Deep Learning anwenderfreundlich und lizenzfrei u.a. in Phython integriert worden.
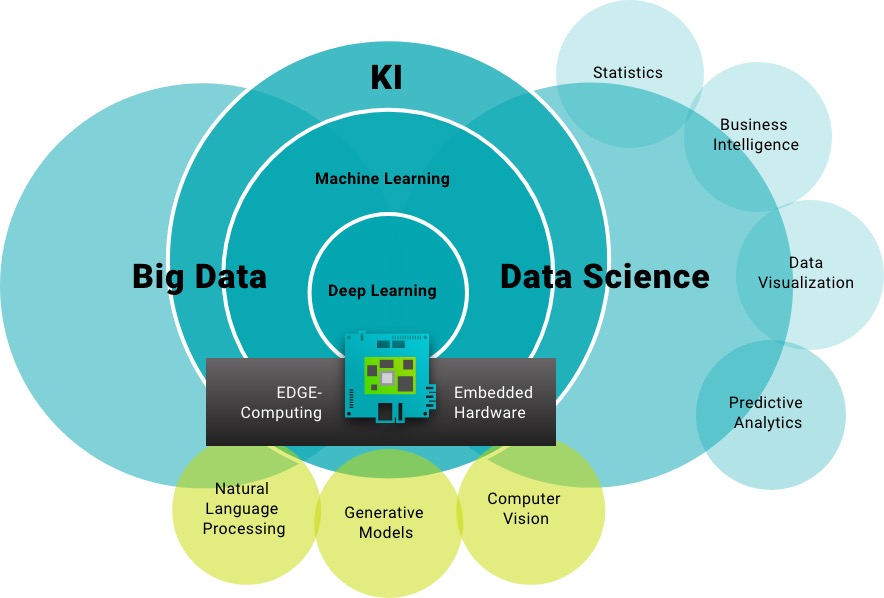
Diese drei Begriffe bezeichnen Unterkategorien Künstlicher Intelligenz.
Machine Learning
bezeichnet das Lernen aus Beispielen. Der Algorithmus lernt dabei nicht alle Beispiele auswendig, sondern erlernt die Grundcharakteristik der Beispiele und kann diese anschließend auf ungesehene Daten anwenden.
Deep Learning
ist eine Unterkategorie von Machine Learning und arbeitet nach ähnlichen Prinzipien. Der entscheidende Unterschied ist das selbstständige adaptieren der Parameter, um optimierte Ergebnisse zu erhalten. Mit Deep Learning lassen sich komplizierte Fragestellungen mit multiplen, nichtlinearen Abhängigkeiten lösen.
Big Data
bezeichnet die Verwendung von großen Datenmengen, die durch Ihre Größe nicht mit herkömmlichen Mitteln bearbeitet werden können. Big Data kann mit Machine Learning oder Deep Learning analysiert werden.
Ohne Hardware läuft nichts _ Smarte Embedded Systeme mit integriertem Machine Learning
Daten sammeln, speichern, strukturieren und analysieren sind die Herausforderungen für den Einsatz Künstlicher Intelligenz. Das rechenaufwendige an KI ist das Erstellen eines Modells. Gleichzeitig wird Hardware benötigt, die diese Daten aufzeichnet, vorverarbeitet, zum Computer / Server sendet oder selbst verarbeitet.
Um als Edge Device optimale Funktionalität zu gewährleisten, muss die Hardware ebenso leistungsstark wie energiesparsam sein. PHYTEC verbindet die Bausteine aus jahrelanger Erfahrung im Bereich Hardwareentwicklung und Kernel-/ Software-Entwicklung mit Expertise im Bereich Data Analytics. Steigen Sie direkt mit unseren AI Kits in die KI-Entwicklung ein.

KI-Experte Dr. Jan Werth _ auf der Embedded World 2020
Online-Seminare _ Hilfreiches Embedded-Wissen kompakt erklärt in kurzen Video-Sessions

In informativen Online-Seminaren mit unseren Experten und Partnern informieren wir Sie über spannende Themen aus der Embedded-Branche.
Sie erhalten kostenfreien Einblick in neue Hard- und Software-Lösungen und erfahren mehr zu besonderen Angeboten.
Unsere Embedded Experten sind für Sie da!
Sichern Sie sich schnell, einfach und kostenfrei Ihren persönlichen Beratungstermin.
30 Minuten exklusiv für Sie und Ihr Projekt!
Weitere interessante Themen: